

The dawn of a new era in artificial intelligence has arrived, marked by groundbreaking innovations in video-language understanding. At the center of this transformation lies an enigma: how can machines interpret the complexity of dynamic video content and align it seamlessly with human language? This question fuels a race to push the boundaries of video-language AI, which remains fraught with challenges such as computational inefficiency and limited temporal comprehension. Enter Video-Panda, a disruptive, encoder-free architecture that claims to revolutionize this domain by balancing performance, efficiency, and scalability. With just 45 million parameters — a fraction of its competitors’ size — Video-Panda offers a glimpse into the future of lightweight, highly efficient AI systems. But how does it achieve this delicate balance, and what does it mean for the future of video-language intelligence?
The Heart of Efficiency: Encoder-Free Design
Traditional video-language models depend heavily on pretrained encoders, often ballooning to billions of parameters. These architectures extract features from individual frames or sequences of images and align them with language models through complex mechanisms like Q-Formers or projection layers. While effective, this approach introduces substantial computational overhead and delays.
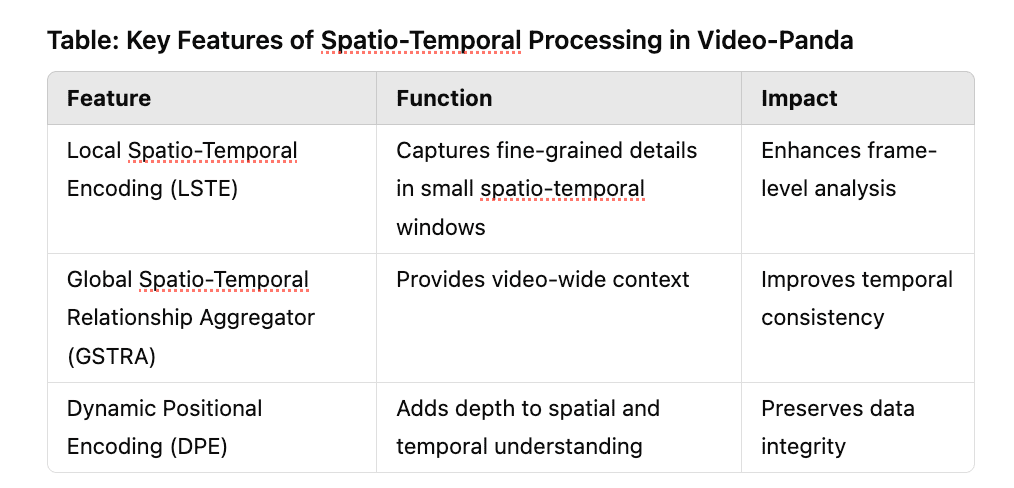
Video-Panda takes a radically different route. By eliminating the need for encoders altogether, it employs the innovative Spatio-Temporal Alignment Block (STAB) to process videos directly. STAB comprises two key mechanisms: Local Spatio-Temporal Encoding (LSTE) and Global Spatio-Temporal Relationship Aggregator (GSTRA). These components allow the model to capture both fine-grained frame-level details and overarching video-level context. A dynamic positional encoding (DPE) layer adds depth to the analysis, ensuring that every frame’s spatial and temporal nuances are preserved.
The result? Video-Panda processes videos up to 4x faster than traditional encoder-heavy models like Video-ChatGPT, offering competitive performance on benchmarks such as MSVD-QA and ActivityNet-QA. This efficiency redefines the feasibility of real-time video comprehension.
Unlocking Temporal Intelligence
Understanding video requires more than just identifying objects in individual frames — it necessitates grasping temporal relationships. How does Video-Panda excel where others stumble?
The architecture’s use of LSTE enables it to analyze short, overlapping spatio-temporal windows, capturing subtle changes across frames. Meanwhile, GSTRA aggregates global video-level context, bridging gaps between local observations and the broader narrative. This dual approach allows Video-Panda to maintain temporal consistency, avoiding common pitfalls like misinterpreting sequential events.
To visualize this, consider a video of a dog fetching a ball. Traditional models might falter, focusing on isolated frames — the dog running, the ball in midair, or the retrieval itself — without understanding their chronological order. Video-Panda, by contrast, threads these events into a cohesive story, attributing meaning to the sequence as a whole.
Speed Meets Scalability
One of Video-Panda’s standout features is its incredible scalability. Achieving high performance on video benchmarks often requires substantial computational resources, making real-time applications challenging. With its compact design, Video-Panda achieves efficiency without sacrificing accuracy.
Compared to Video-LLaVA, which uses 425M parameters, or Video-ChatGPT, with 307M parameters, Video-Panda’s 45M-parameter design reduces computational requirements by 6.5x or more. This lean architecture enables faster inference times (41 ms per video vs. 171 ms for Video-ChatGPT), making it ideal for deployment in real-world scenarios, from autonomous vehicles to video streaming analytics.
The benefits don’t stop at processing speed. Video-Panda’s training approach, which gradually scales dataset complexity, ensures robust generalization across diverse tasks. By fine-tuning with a mixture of instructional and open-ended datasets, it achieves state-of-the-art results in both zero-shot and supervised evaluations.
How Machines Learn to Think Temporally
While other models treat videos as sequences of static images, Video-Panda integrates temporal reasoning directly into its architecture, unlocking nuanced event comprehension.
Faster, Leaner, Smarter
At 45M parameters, Video-Panda punches far above its weight, delivering performance comparable to models several times its size.
Spatio-Temporal Synergy
By blending local and global perspectives, Video-Panda provides insights that neither traditional image models nor basic video models can achieve.
Ethics by Design
Built on publicly available datasets, Video-Panda avoids ethical pitfalls while reducing computational overhead, offering an eco-friendly alternative.
A Vision Beyond Frames
The encoder-free design invites possibilities for analyzing longer videos and handling multimodal inputs like audio and subtitles.
Charting the Future of Video-Language AI
The innovations introduced by Video-Panda herald a future where video-language models are not just powerful but also accessible and sustainable. As the demands on AI systems grow — from streaming analytics to real-time decision-making — Video-Panda’s efficient approach could reshape the industry.
Imagine a world where your AI assistant can summarize hours of video in minutes, track live events with pinpoint accuracy, or even provide real-time insights into complex scenes. Video-Panda’s encoder-free architecture proves that such aspirations are not only feasible but imminent. By pioneering lightweight, scalable solutions, it offers a hopeful vision: one where technological advancements are driven by both performance and practicality.
About Disruptive Concepts
Welcome to @Disruptive Concepts — your crystal ball into the future of technology. 🚀 Subscribe for new insight videos every Saturday!
See us on https://twitter.com/DisruptConcept
Read us on https://medium.com/@disruptiveconcepts
Enjoy us at https://disruptive-concepts.com
Whitepapers for you at: https://disruptiveconcepts.gumroad.com/l/emjml





