

Picture a machine that can understand not just what we say, but what we do every day, like cooking, cleaning, and even paragliding. LLAVIDAL is a Large Language Vision Model that brings this to reality by recognizing and interpreting our daily activities with unprecedented accuracy. Developed to process complex human-object interactions and spatiotemporal relationships, LLAVIDAL is trained on the ADL-X dataset. This dataset comprises 100K RGB video-instruction pairs, language descriptions, 3D skeletons, and action-conditioned object trajectories. Unlike traditional models trained on web videos, LLAVIDAL excels in understanding the randomness and subtleties of real-life activities, making it a game-changer for applications in healthcare, eldercare monitoring, and robotic assistance.
The Power of 3D Poses in LLAVIDAL
One of the most exciting features of LLAVIDAL is its ability to incorporate 3D poses into its understanding framework. By analyzing the movements of critical body parts, LLAVIDAL can grasp the fine details of human actions. This is crucial for activities of daily living (ADL), where actions can be complex and nuanced. The 3D poses are processed through a specialized model called PoseLM, which translates these movements into language contextualized features. This allows LLAVIDAL to generate detailed and accurate descriptions of human activities, paving the way for more sophisticated and human-like interactions between machines and users.
Enhancing Interaction Understanding
LLAVIDAL’s ability to track and understand objects is another leap forward. By using advanced models like BLIP-2 and ObjectLM, LLAVIDAL can detect and follow objects within a scene, even as they move and interact with humans. This is particularly important for understanding activities where objects play a central role, such as cooking or using tools. The model can identify relevant objects, track their trajectories, and integrate this information with human actions, providing a comprehensive understanding of the scene. This capability not only enhances activity recognition but also opens up new possibilities for intelligent assistance systems.
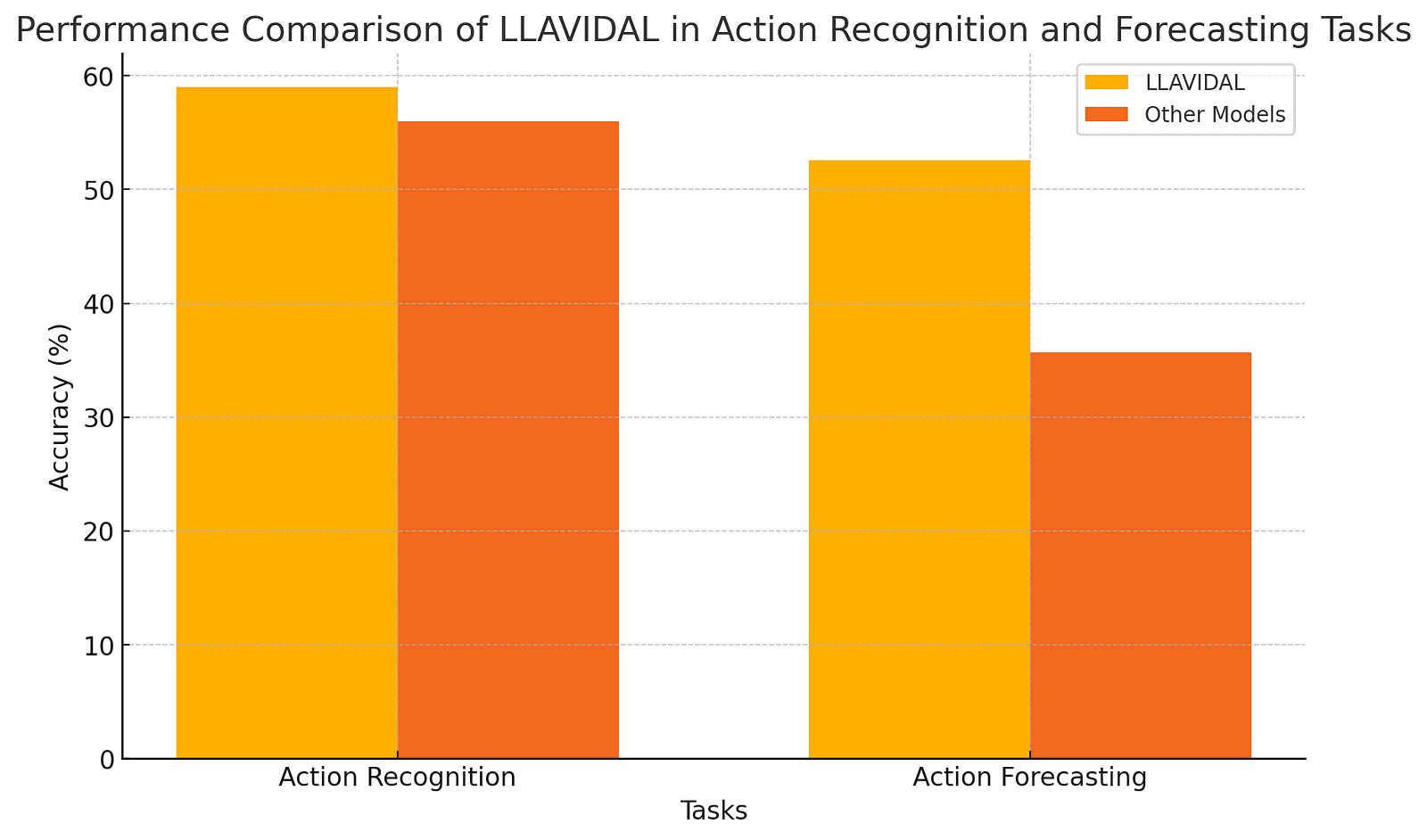
Benchmarking Excellence
To validate its effectiveness, LLAVIDAL has been rigorously benchmarked against other leading models. It outperforms competitors in key metrics such as action recognition and forecasting. Using datasets like Charades and Toyota Smarthome, LLAVIDAL achieves higher accuracy in recognizing complex activities and predicting future actions. This superior performance is a testament to the power of the ADL-X dataset and the innovative integration of 3D poses and object tracking. LLAVIDAL’s ability to handle the unstructured nature of daily activities makes it a standout model in the field of vision and language integration.
The graph below demonstrates the superior performance of LLAVIDAL compared to other models in action recognition and forecasting tasks.
A New Horizon in AI
The development of LLAVIDAL marks a significant step forward in the field of artificial intelligence. By enabling machines to understand and interact with the human world in more nuanced ways, we can unlock new levels of automation and assistance. Imagine robots that can help with daily chores, AI systems that monitor and support eldercare, and intelligent agents that understand our routines and preferences. The potential applications are vast and transformative. LLAVIDAL’s advancements bring us closer to a future where AI seamlessly integrates into our lives, enhancing our capabilities and improving our quality of life.
3D Pose Integration
LLAVIDAL’s integration of 3D poses allows it to understand the intricate movements of body parts. By focusing on five key joints — head, hands, and knees — LLAVIDAL can provide detailed descriptions of actions. This precision is crucial for recognizing complex activities and ensuring accurate interaction with the environment.
Object Tracking Mastery
Using advanced object tracking, LLAVIDAL can identify and follow objects through a scene. This capability enhances its understanding of activities that involve multiple interactions with various objects, such as cooking or cleaning, providing a more holistic view of daily tasks.
Real-World Dataset
LLAVIDAL is trained on the ADL-X dataset, which includes 100K video-instruction pairs and detailed annotations. This dataset captures the randomness and complexity of daily activities, making LLAVIDAL exceptionally adept at understanding real-world scenarios.
Benchmark Dominance
LLAVIDAL outperforms other models in benchmarks like Charades and Toyota Smarthome. Its superior accuracy in action recognition and forecasting showcases its advanced capabilities in understanding and predicting human activities, setting a new standard in the field.
Healthcare Potential
LLAVIDAL’s ability to understand daily activities has significant implications for healthcare. It can be used for eldercare monitoring, cognitive decline assessment, and developing robotic assistants, improving the quality of care and support provided to individuals in need.
Transforming AI
The future looks incredibly promising with LLAVIDAL. As it continues to evolve, we can expect even more sophisticated interactions between humans and machines. Imagine a world where AI understands your daily routine and assists you seamlessly. LLAVIDAL is a step towards that future, where technology not only simplifies our lives but also enriches them. Its potential to revolutionize healthcare, home automation, and beyond is immense. Let’s embrace this exciting journey and look forward to the incredible innovations that LLAVIDAL will bring to our world.
About Disruptive Concepts
https://www.disruptive-concepts.com/
Welcome to @Disruptive Concepts — your crystal ball into the future of technology. 🚀 Subscribe for new insight videos every Saturday!
Discover the Must-Have Kitchen Gadgets of 2024! From ZeroWater Filters to Glass Containers, Upgrade Your Home with Essential Tools for Safety and Sustainability. Click Here to Transform Your Kitchen Today!





