

Code generation is typically an all-or-nothing endeavor for today’s large language models (LLMs). Unlike the slow, methodical way a developer builds software — adding, testing, and improving line-by-line — LLMs attempt to synthesize everything in a single swing. The outcome? Often, it’s a mess of bugs, and worse, a loss of control over the nuances of how solutions evolve. This, in essence, is the foundational problem LintSeq aims to solve: the difference between how code is born versus how it grows.
Code as a Conversation, Not a Monologue
Enter LintSeq: a technique that transforms the traditional single-shot code synthesis approach into a sequential process of building, refining, and correcting — just like a meticulous human coder. By leveraging a “linter” to generate clean, error-free sequences of code edits, LintSeq allows smaller models to match, and sometimes outperform, their larger counterparts.
Think of this shift as the difference between yelling an entire speech at once versus engaging in an attentive conversation. LintSeq models are effectively having a dialogue with the code — understanding the logical progression from a blank slate to a well-defined solution. By framing code generation as an evolving, step-by-step process, the algorithm taps into the incremental creativity at the heart of programming.
Smarter AI Models Through Sequential Learning
The LintSeq approach starts with a backward journey: it takes an entire program, systematically “unwinds” it by deleting lines, and, with the help of a linter, checks if each resulting fragment remains error-free. The cleaned, backward trajectory is then reconstructed in the forward direction, creating a series of edit “snapshots” — like watching a house being rebuilt brick-by-brick from a previously demolished state. Training language models with this kind of granular, constructive sequence data yields models that exhibit an impressive knack for logical, incremental problem-solving.
Unlike traditional methods where models generate sprawling pieces of code in a single go, often resulting in redundancy or mistakes, LintSeq provides small, purposeful increments. Each edit not only advances the code but adheres to a set of logical constraints defined by its previous state. This makes models trained on LintSeq data more adaptable, allowing them to generate diverse and high-quality solutions with fewer errors.
Code Diversity and Efficiency: The True Disruption
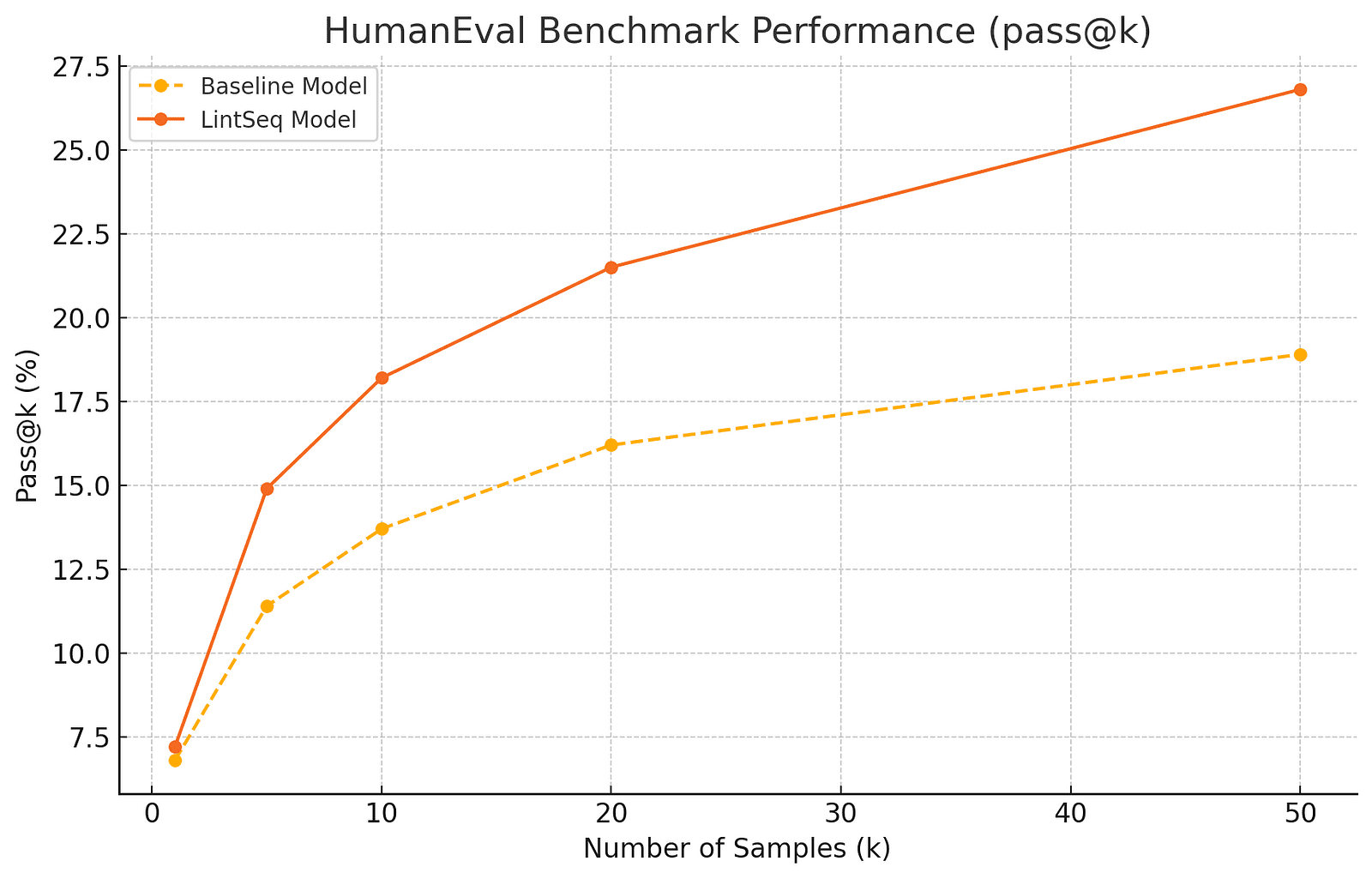
Here lies the true disruptive force of LintSeq: it fundamentally changes the economics of AI training and inference. Smaller LLMs fine-tuned on synthetic edit sequences are now capable of generating code that’s not only more diverse but often just as functional as the outputs from larger models like GPT-4. For example, on the HumanEval benchmark, LintSeq-trained models increased coverage by 20% in pass@50 compared to models trained with standard methods.
Moreover, repeated sampling from these LintSeq-enhanced models shows a remarkable boost in problem-solving efficiency. It means a more economical trade-off between computational cost and solution accuracy — a major win, particularly for smaller devices running lightweight models. With a modest parameter size of 150M, these models can achieve or even surpass the performance of models with twice as many parameters. The significance of this development isn’t just technical; it’s democratizing. More devices — laptops, phones, embedded systems — can now perform high-quality code synthesis without needing immense computational power.
Below is a graph illustrating the HumanEval benchmark performance (pass@k) of LintSeq-enhanced models compared to traditional models at various sample counts:
Unlocking the True Power of Linters
Linters are typically used as secondary tools — like grammar checkers for code. LintSeq transforms them into guiding forces for creating synthetic training data that makes AI more efficient and smarter.
Better Results from Smaller Models
Tiny models trained on LintSeq outperformed baseline models and even matched performance with models twice their size, turning the preconception of “bigger is better” on its head.
Error-Free Edit Generation
By focusing on only the error-free pathways during backward sampling, LintSeq produces a model that inherently learns how to avoid common coding mistakes, increasing its reliability.
A Step-by-Step Approach to Creativity
Training models on code edits rather than full programs results in outputs that reflect a deliberate, stepwise creative process. This approach makes models adept at handling complex, structured programming tasks without falling into common pitfalls.
From Speech to Conversation
By framing code generation as a sequence of edits, LintSeq shifts the model’s approach from one-off monolithic attempts to something more akin to interactive refinement — bridging the gap between human and machine coding processes.
Reinventing AI-Coder Collaboration
The implications of LintSeq are profound, but not just because of its technical merits. It hints at a future where small models work alongside us, offering an inexpensive, intelligent co-coding experience. With tools like LintSeq, we may soon find AI capable not only of creating sophisticated programs but also of meaningfully engaging with the human creative process — helping developers at every stage, from debugging to brainstorming.
It’s a future where AI isn’t just powerful because of size, but smart because of how well it thinks alongside us, one purposeful edit at a time.
About Disruptive Concepts
Welcome to @Disruptive Concepts — your crystal ball into the future of technology. 🚀 Subscribe for new insight videos every Saturday!
See us on https://twitter.com/DisruptConcept
Read us on https://medium.com/@disruptiveconcepts
Enjoy us at https://www.disruptive-concepts.com
Whitepapers for you at: https://disruptiveconcepts.gumroad.com/l/emjml





