

Today’s AI research is filled with buzzwords — “scaling,” “parallelism,” “memory efficiency” — but MT-NLG 530B has taken these concepts to unprecedented heights. MT-NLG, a joint project by Microsoft and NVIDIA, pushes the boundaries of language modeling with a jaw-dropping 530 billion parameters, setting new benchmarks in natural language generation. What makes MT-NLG unique isn’t just size; it’s the custom-built infrastructure of DeepSpeed and Megatron-LM that powers it, fusing 3D parallelism with unmatched efficiency.
So, why is all this significant? Because MT-NLG isn’t just a model — it’s a step towards models that can learn in ways we haven’t seen before. Its massive parameter count and sophisticated architecture enable it to exhibit zero- and few-shot learning capabilities, performing complex tasks with little to no additional training. And beyond the stats, MT-NLG represents the dream of AI that approaches human understanding, promising to redefine what’s possible in artificial intelligence.
Infrastructure Redefined
Training a model of this magnitude demands more than raw computing power. Imagine cramming the equivalent of 10 terabytes of data into a single GPU’s memory — impossible without innovations in data handling and parallelism. MT-NLG’s developers took on the formidable challenge of not only managing but optimizing 530 billion parameters across clusters of GPUs. With NVIDIA A100 GPUs and sophisticated DeepSpeed software, they engineered a system that redefines data, tensor, and pipeline parallelism, optimizing both memory and computational power.
At its core, this model combines data and tensor-slicing with pipeline parallelism in a 3D arrangement that minimizes bottlenecks. In this structure, data travels as swiftly as it’s processed, using NVIDIA’s top-tier InfiniBand networking to maintain high-speed communications across thousands of GPUs. This setup, termed 3D parallelism, elevates MT-NLG’s capabilities to extraordinary levels, balancing memory load and computational strain to make this record-breaking model a reality.
The Building Blocks of MT-NLG’s Intelligence
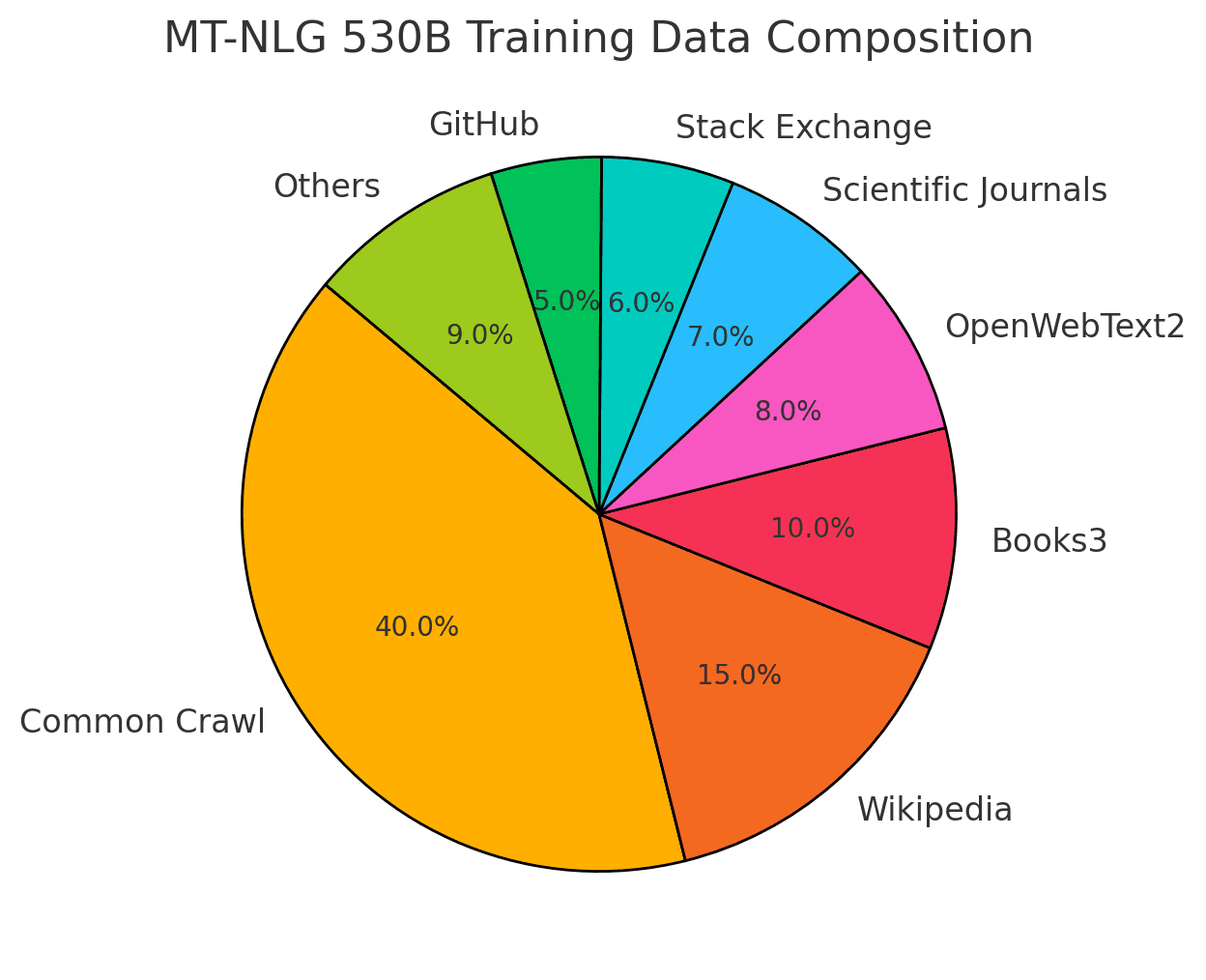
But what good is a model if it doesn’t learn? Building MT-NLG’s intelligence involved a meticulously curated dataset, incorporating sources from Common Crawl to Wikipedia, to rare scientific papers. The data underwent a rigorous curation process, ensuring diversity and quality to maximize MT-NLG’s understanding of language. Only the best linguistic materials made it into the training corpus, where a 339-billion-token dataset was distilled into the foundation of MT-NLG’s knowledge.
Training on this massive dataset posed its own challenges. Memory management techniques — gradient accumulation, micro-batching, and tensor-slicing — ensured that all 530 billion parameters were trained without overwhelming the GPUs. These complex data-handling methods ensured MT-NLG not only learned efficiently but also retained an impressive command of nuanced linguistic tasks, from natural language inference to commonsense reasoning.
The graph below shows the distribution of dataset sources, displaying the percentage contribution of each category like Common Crawl, Wikipedia, and scientific sources.
Rethinking Language Models in the Context of Bias
Large models like MT-NLG learn from data, which means they’re as unbiased — or biased — as the sources they train on. Researchers found MT-NLG reflected societal biases present in the data, showing disparities in word associations tied to gender, race, and other social categories. Interestingly, MT-NLG’s 3D parallelism enables not only data scaling but also control over bias handling, with researchers applying filters and tuning parameters to reduce bias in its outputs.
While addressing bias in models this large is far from straightforward, MT-NLG’s design allows researchers to navigate these challenges more effectively. By focusing on refining the model’s sensitivity to context, MT-NLG 530B represents a promising step forward in mitigating bias — an essential feature as AI becomes more integrated into daily life.
Milestones on MT-NLG’s Journey
- Memory Efficiency: With 10 terabytes of memory demand, MT-NLG’s use of 3D parallelism redefines what’s possible in scaling AI models.
- Zero- and Few-Shot Learning: The model excels in zero-shot and few-shot learning, making leaps in commonsense reasoning, reading comprehension, and natural language inference.
- Data Volume and Quality: Trained on 339 billion tokens from highly curated datasets, MT-NLG performs with unprecedented linguistic insight.
- Hardware Ecosystem: NVIDIA’s A100 GPUs and DeepSpeed software enable MT-NLG to maximize speed and efficiency, operating at 1.4 exaFLOP/s peak precision.
- Bias Mitigation Techniques: MT-NLG incorporates advanced data-handling and filtering techniques to tackle the complex issue of social bias in AI.
A New Era for Artificial Intelligence
In the end, MT-NLG isn’t just a milestone for Microsoft and NVIDIA; it’s a groundbreaking example of where AI technology is headed. The successful training of MT-NLG 530B exemplifies how advancements in parallelism, memory handling, and data curation are the keys to AI’s future. As researchers continue to refine models like MT-NLG, we’re on the brink of systems that can reason, intuit, and adapt with unprecedented sophistication. The future of AI is vast, full of untapped potential, and models like MT-NLG are lighting the way forward.
Welcome to @Disruptive Concepts — your crystal ball into the future of technology. 🚀 Subscribe for new insight videos every Saturday!
See us on https://twitter.com/DisruptConcept
Read us on https://medium.com/@disruptiveconcepts
Enjoy us at https://disruptive-concepts.com
Whitepapers for you at: https://disruptiveconcepts.gumroad.com/l/emjml





