

Neural networks, those metaphorical black boxes, are notoriously hard to interpret. But imagine a novel toolset, a gateway, that cracks them open to reveal the underlying gears. Enter Switch Sparse Autoencoders (SAEs) — a disruptive technology that doesn’t just repackage existing solutions but reimagines them to slice through computational barriers. Think of them like an orchestra, where small specialized ensembles — “experts” — play their part precisely when needed, keeping the music both elegant and efficient.
Scaling Made Elegant
Traditional SAEs face a dilemma: they need to grow enormously wide to represent all the features within high-capacity models. This leads to computational and memory bottlenecks. Switch SAEs cleverly sidestep this problem by borrowing tricks from the “sparse mixture of experts” playbook. The key insight? Use many smaller expert networks and a smart routing mechanism that decides which expert should work on each input. The result is a dramatic improvement in computational efficiency without compromising quality — essentially getting more bang for the same buck.
Feature Geometry and Duplication
As with any system, elegance comes with its complexities. For Switch SAEs, the magic is in balancing the specialization and redundancy of the features each expert learns. Picture this: clusters of small specialists, each responsible for a niche, yet some overlap to ensure no part of the task is forgotten. This delicate trade-off creates a robust model that reconstructs inputs with fewer resources. The Switch SAE avoids the trap of polysemantic neurons — those “jack of all trades” that activate on wildly different inputs — leading to more interpretable features for humans trying to peek into the system.
The Future of Training Efficiency
Switch SAEs point to a future where the biggest models are trained not by brute force but by intelligent allocation of resources. Just like optimizing a power grid, only a few components need to light up for specific tasks. This ability to maintain — or even enhance — interpretability while cutting down on computational costs is a leap toward the broader goal of making models transparent and accessible. It’s a kind of efficiency that’s as poetic as it is practical, channeling each bit of processing power into maximum utility.
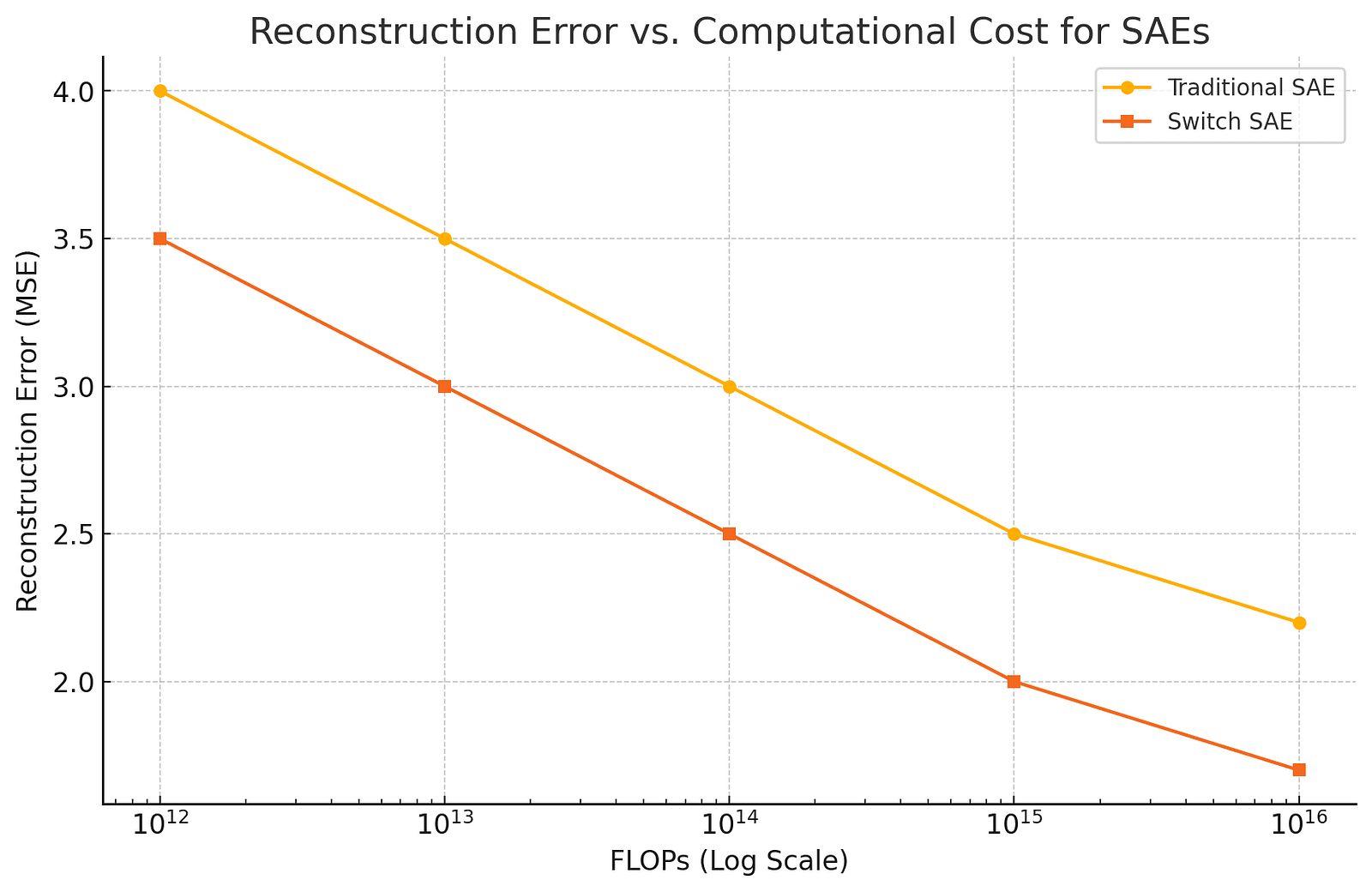
To highlight the efficiency gains of Switch Sparse Autoencoders, we provide a graph illustrating the relationship between computational cost (measured in FLOPs) and reconstruction error.
A Symphony of Experts
Each Switch SAE is made up of smaller “expert” autoencoders. Rather than using every neuron for every input, the system routes inputs only to the relevant experts, ensuring specialized and optimized responses.
Feature Duplication: A Calculated Trade-off
Switch SAEs purposely duplicate some features across experts, which helps in reducing the likelihood of missing critical features but slightly reduces efficiency. This balance keeps the model both broad in its understanding and precise in its execution.
Scaling Benefits Without the Costs
Compared to traditional SAEs, Switch SAEs achieve a better mean squared error with fewer FLOPs (floating point operations). They achieve roughly one order of magnitude less compute cost while maintaining similar reconstruction accuracy.
FLOP-Matched Flexibility
When matching the computational budget (FLOPs), Switch SAEs outperform other architectures in both loss recovery and reconstruction error. Essentially, they do more with the same amount of power — improving the Pareto frontier of AI model performance.
Geometry Revealed through t-SNE
Switch SAEs reveal distinct clustering behavior when visualized using t-SNE. Encoder features from the same expert form tight clusters, showcasing the specialization enforced by the routing mechanism — a clear visual testament to how efficiently the model learns.
A Disruptive Leap Forward in Model Interpretability
Switch Sparse Autoencoders offer a hopeful vision for the future of neural networks: models that are not just bigger, but smarter. By tackling the entrenched inefficiencies in feature extraction, Switch SAEs show us a path toward more transparent and interpretable AI. The future holds the possibility of neural networks that can not only perform complex tasks but also explain how they did so — in terms we can all understand.
About Disruptive Concepts
Welcome to @Disruptive Concepts — your crystal ball into the future of technology. 🚀 Subscribe for new insight videos every Saturday!
See us on https://twitter.com/DisruptConcept
Read us on https://medium.com/@disruptiveconcepts
Enjoy us at https://disruptive-concepts.com
Whitepapers for you at: https://disruptiveconcepts.gumroad.com/l/emjml





