

As artificial intelligence models grow in ambition — 12 billion parameters, anyone? — the push for better image quality leads to a different frontier: computational paralysis. Enter SVDQuant, a clever pivot from conventional quantization, reshaping the path for 4-bit processing. Think of it as re-imagining a complex orchestra, with some instruments playing softer to make space for the powerful crescendos. By shifting outliers from activations to weights and capturing the overflow with a low-rank symphony, SVDQuant harnesses 16-bit finesse where it’s needed most. The result? A dance of precision that defies the heavy hand of computational excess.
Absorbing Outliers, Forging Performance
Outliers are tricky. They lurk in the unpredictable extremes of data, making quantization a risky bet. But SVDQuant doesn’t merely play the odds; it changes them. Conventional methods struggle as if trying to herd cats — wild, independent variables slipping through the cracks. SVDQuant elegantly sidesteps this by migrating outliers into a low-rank branch, like scooping up errant notes into a sub-melody that elevates the whole piece. Its brilliance lies in making ‘good enough’ a calculated art form, squeezing efficiency out of 4 bits without blurring the edges of visual fidelity.
Nunchaku: Fusing Precision and Speed
Consider the operational ballet of running a diffusion model on an RTX 4090 laptop — a marvel in raw power, yes, but not immune to the pitfalls of memory strain. SVDQuant’s companion, the Nunchaku inference engine, fuses the low-rank and low-bit branches in a seamless routine, slicing latency and weaving shared outputs. The outcome isn’t just speed — it’s smart speed. No unnecessary reads, no wasteful data shuffling. Just a lithe, unified leap forward where low-rank efficiency and quantization meet.
Where Quantization Becomes Art
To call SVDQuant merely a ‘method’ would be reductive. It’s a philosophical shift in how AI harnesses complexity, trading brute-force scaling for a sculptor’s touch — chiseling memory use and latency down to a more human scale. As GPUs evolve, and the appetite for interactive AI on personal devices swells, SVDQuant hints at a future where high-res doesn’t mean high lag.
Insights from SVDQuant’s Application
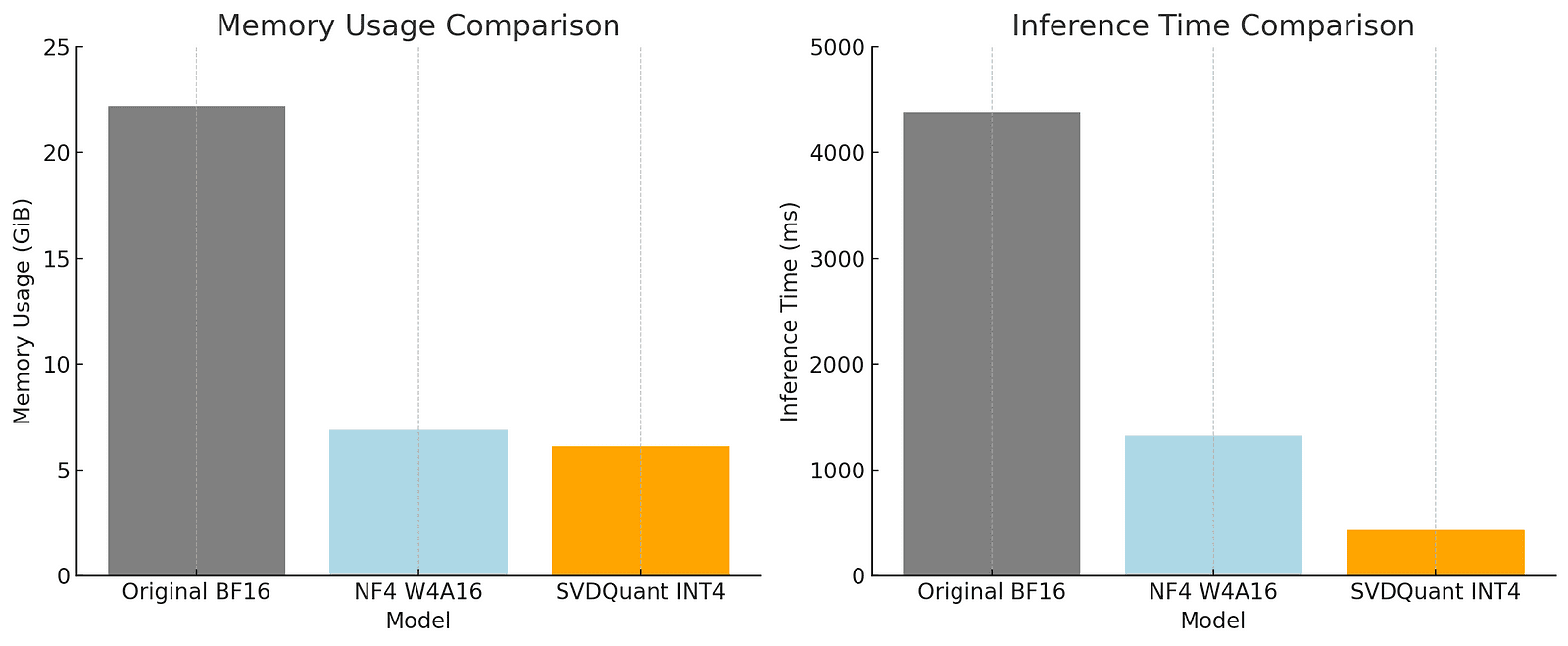
Massive Memory Reduction: With SVDQuant, models like FLUX.1 achieve a 3.6x reduction in size — shrinking from 22.2 GiB to 6.1 GiB without sacrificing performance.
Speed Marvels: The Nunchaku engine showcases up to 10.1x faster inference on 16GB GPUs, transforming laptops from mere AI observers to participants.
Visual Fidelity Maintained: Unlike typical 4-bit models that suffer, SVDQuant’s integrated low-rank approach preserves image quality, scoring higher on visual tests.
Off-the-Shelf Adaptability: Integration with LoRA models means SVDQuant doesn’t demand re-quantization, simplifying complex fine-tuning processes.
Proven Across Architectures: From UNet to DiT backbones, SVDQuant demonstrates versatility, applying its outlier-absorbing magic across the board.
To illustrate the significant impact on memory and inference efficiency, the following chart highlights the comparison across models.
Charting Tomorrow’s Path
The story of SVDQuant is a testament to innovation born from necessity — taking a magnifying glass to inefficiencies and rendering them obsolete. It’s not just a glimpse into what AI could do but what it should do: operate smarter, not just bigger. With every outlier absorbed and bit made efficient, SVDQuant sketches out a new blueprint for AI, where sleek performance and massive-scale models can finally coexist.
About Disruptive Concepts
Welcome to @Disruptive Concepts — your crystal ball into the future of technology. 🚀 Subscribe for new insight videos every Saturday!
See us on https://twitter.com/DisruptConcept
Read us on https://medium.com/@disruptiveconcepts
Enjoy us at https://disruptive-concepts.com
Whitepapers for you at: https://disruptiveconcepts.gumroad.com/l/emjml





