

In a world driven by rapid advancements in artificial intelligence and hardware optimization, the concept of lookup tables (LUTs) has emerged as a cornerstone for efficient computation. ReducedLUT, a groundbreaking method, promises to redefine hardware efficiency by leveraging “don’t care” conditions for optimal compression without compromising neural network performance. By shrinking hardware footprints while maintaining near-perfect accuracy, ReducedLUT is poised to transform the landscape of AI implementations.
The Evolution of LUTs: From Bottlenecks to Breakthroughs
Efficient implementation of mathematical computations using Logical Lookup Tables (L-LUTs) often surpasses the capabilities of Field Programmable Gate Arrays (FPGAs). Historically, the exponential growth of L-LUTs due to high input resolutions has presented a significant challenge. Traditional methods like piecewise polynomial approximations or multipartite table decomposition focus on breaking larger tables into smaller components. However, the irregular patterns inherent in neural networks — a staple of modern AI — render these methods less effective.
ReducedLUT enters this narrative as a game-changer. By incorporating “don’t care” conditions, which identify irrelevant or rare input-output mappings, ReducedLUT introduces flexibility into the compression process. This innovation paves the way for self-similarity detection, allowing complex neural network functions to be compressed with minimal loss of accuracy — a feat unachievable by traditional methods.
A Methodology Rooted in Innovation
ReducedLUT operates through a multi-step process aimed at redefining LUT efficiency. The first step involves training-based interpolation to identify unobserved patterns in neural network datasets, marking them as “don’t cares.” These entries are then strategically replaced to maximize compression by aligning sub-table dependencies.
A graph showcasing the P-LUT utilization vs. exiguity demonstrates the power of ReducedLUT. For instance:
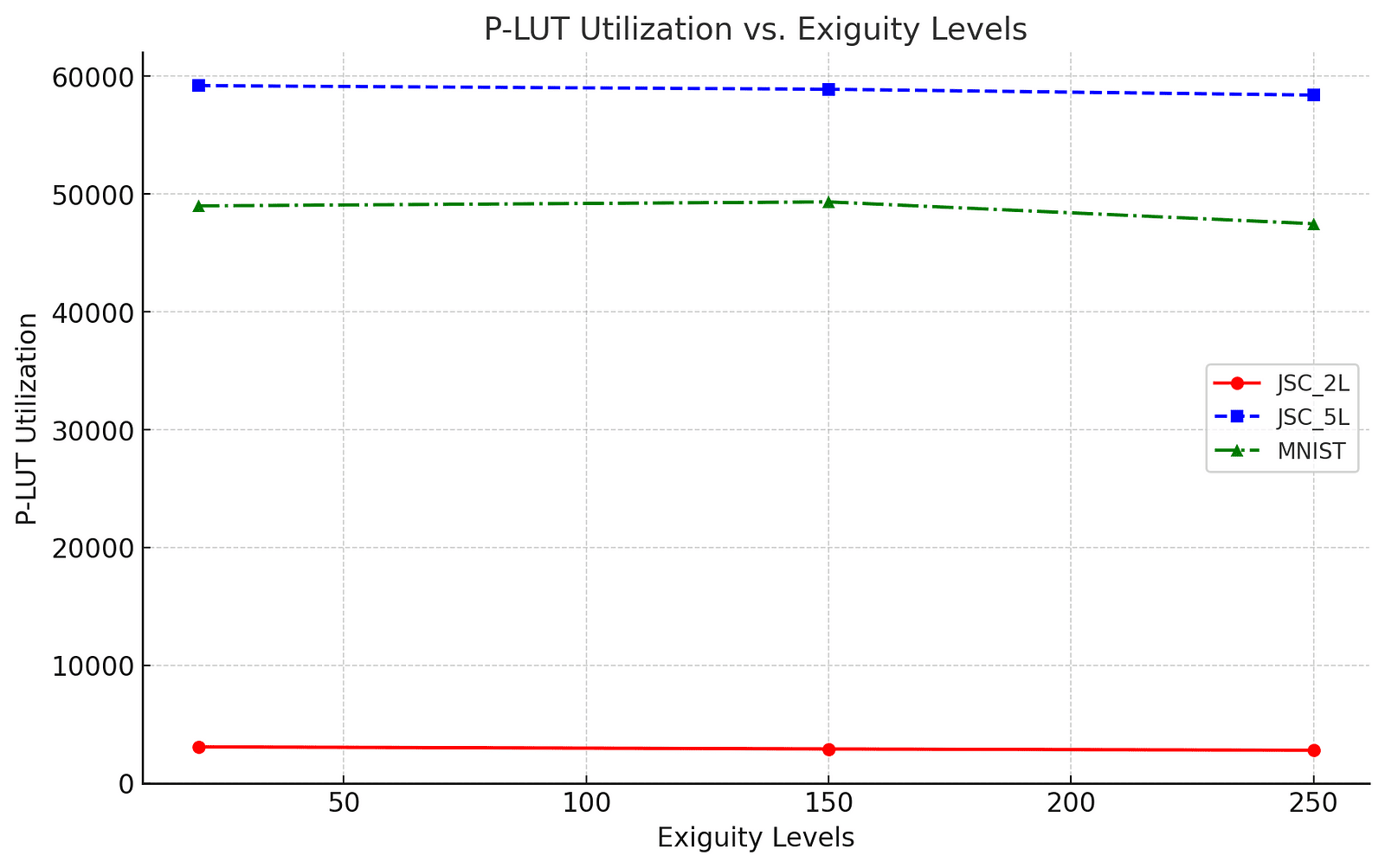
Transformative Applications in Neural Networks
Neural networks, notorious for their complexity and over-parameterization, benefit immensely from ReducedLUT’s approach. The tool’s ability to identify and compress irregular data patterns has yielded remarkable results. For example, ReducedLUT achieved up to 39% reduction in P-LUT utilization for models like JSC_5L, maintaining test accuracy within a negligible margin. This unprecedented efficiency highlights its potential for scaling AI applications in data-intensive fields like particle physics and real-time classification tasks.
Limitations and Future Horizons
While ReducedLUT excels in preserving accuracy, its compression gains are limited by datasets with high local variation and fewer self-similarities, as seen in MNIST models. However, its scalability and adaptability provide a promising foundation for future enhancements. The inclusion of rare but non-critical values into the “don’t care” set and optimization across grouped LUTs could further amplify its impact. With ongoing research, ReducedLUT’s applications may extend beyond neural networks, revolutionizing domains that rely on efficient hardware synthesis.
The Art of “Don’t Care” Compression
By marking unobserved input-output pairs in training datasets as “don’t cares,” ReducedLUT introduces unmatched flexibility, allowing for compression without altering critical functionalities.
Scaling New Heights
ReducedLUT reduced P-LUT utilization by up to 39% in JSC_5L models, setting a benchmark for efficiency in FPGA-based neural network implementations.
Near-Zero Accuracy Drop
Despite aggressive compression, ReducedLUT maintains test accuracy within 0.01%, showcasing its ability to balance optimization with precision.
Inspired by Occam’s Razor
ReducedLUT’s compression approach aligns with the principle of Occam’s Razor, simplifying data structures without losing essential information.
Built for Open Source
As an open-source tool, ReducedLUT encourages collaboration and innovation, paving the way for widespread adoption in academia and industry.
A Future Full of Possibilities
ReducedLUT represents a leap forward in hardware efficiency, enabling AI systems to achieve unprecedented performance levels. As researchers explore its full potential, the method’s adaptability and resilience promise to redefine standards across AI hardware. By bridging the gap between cutting-edge technology and practical implementation, ReducedLUT ushers in a future where every bit of data drives transformative change.
About Disruptive Concepts
Welcome to @Disruptive Concepts — your crystal ball into the future of technology. 🚀 Subscribe for new insight videos every Saturday!
See us on https://twitter.com/DisruptConcept
Read us on https://medium.com/@disruptiveconcepts
Enjoy us at https://disruptive-concepts.com
Whitepapers for you at: https://disruptiveconcepts.gumroad.com/l/emjml





