
The hidden flaw that threatens AI’s next big leap

Can AI truly generate language faster and more efficiently without sacrificing accuracy? This question drives the ongoing evolution of language models, with diffusion models emerging as a promising yet controversial alternative to traditional autoregressive models. While diffusion language models (DLMs) offer a tantalizing prospect of generating multiple tokens in parallel — potentially outpacing conventional models — new research suggests a deeper trade-off between speed and precision. This article explores the theoretical and practical implications of DLMs, exposing their strengths, limitations, and the hidden complexities of their efficiency.
Parallelism vs. Accuracy: The Trade-off at the Heart of Diffusion Models
Diffusion models, originally designed for image generation, have been adapted for text generation with the promise of efficiency gains over traditional autoregressive models. Unlike autoregressive models, which generate text sequentially, DLMs attempt to produce multiple tokens at each step, theoretically reducing generation time.
However, efficiency alone does not define success. A critical metric for evaluating language models is Token Error Rate (TER), which measures how accurately a model predicts individual tokens. Studies indicate that DLMs can achieve near-optimal TER regardless of sequence length, allowing them to produce fluent text with fewer sampling steps than autoregressive models.
Yet, when considering Sequence Error Rate (SER) — a measure of whether the entire generated sequence is correct — DLMs struggle. Unlike autoregressive models, which refine text step-by-step, DLMs must correct errors retroactively, leading to a compounding effect where small inaccuracies can disrupt the entire output. This fundamental difference undermines DLMs’ efficiency in reasoning-intensive tasks, such as logical problem-solving or multi-step calculations.
Computational Cost: Are Diffusion Models Truly Faster?
One of the strongest arguments for diffusion models is their ability to reduce computational cost by generating multiple tokens in parallel. Theoretically, this should result in faster text generation. However, practical experiments suggest a more nuanced reality.
To understand the computational implications, consider the number of neural network executions required per generated sequence. While autoregressive models require L executions (where L is sequence length), DLMs initially seem to offer a more efficient alternative by requiring only a fixed number of steps, independent of L. However, as the required SER accuracy increases, DLMs must take more sampling steps, causing their computational cost to scale linearly with sequence length.
In other words, if a task demands highly accurate sequences, DLMs no longer hold an efficiency advantage over autoregressive models. Given that each DLM sampling step often incurs a higher computational cost than an autoregressive step (due to more complex network operations), their real-world advantage becomes questionable.
Below is a graphical representation of how generative perplexity (a measure of fluency) and sequence error rate evolve with increasing sampling steps.
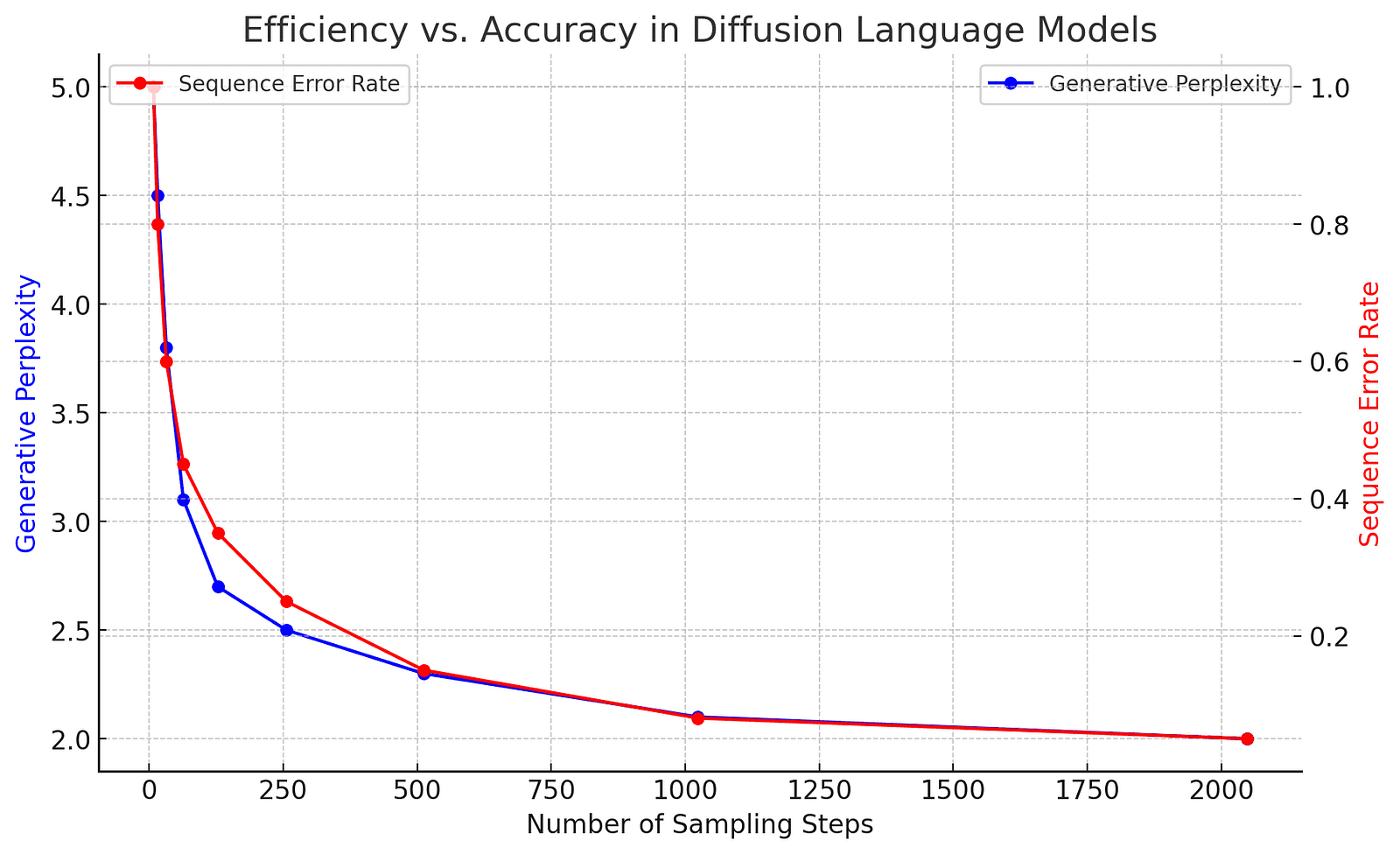
The Future of Diffusion Models: Innovation or Dead End?
Given their efficiency advantages in fluency-focused tasks, diffusion models are well-suited for creative applications like poetry generation, paraphrasing, and content synthesis. However, their struggles with sequence-level correctness raise concerns about their viability in domains requiring strict logical accuracy, such as code generation or mathematical reasoning.
Recent advancements, such as hybrid architectures that combine autoregressive and diffusion approaches, aim to bridge this gap. These models attempt to leverage the efficiency of parallel token generation while incorporating the step-by-step correction mechanisms of autoregressive models. Still, achieving the best of both worlds remains an ongoing challenge.
Compelling Facts That Challenge the Status Quo
How Machines Learn to Think
Diffusion models do not ‘think’ sequentially like humans do. Instead of reasoning step-by-step, they attempt to reconstruct entire sequences at once, leading to unpredictable logical inconsistencies.
Speed vs. Quality: The AI Dilemma
While diffusion models are theoretically faster, their computational cost skyrockets when higher accuracy is required, making them less efficient for precision-heavy tasks.
The Surprising Limitation of Parallel Processing
Generating multiple tokens in parallel seems like an obvious advantage — until errors accumulate across tokens, reducing overall accuracy compared to autoregressive methods.
Can AI Solve Its Own Limitations?
Some hybrid models attempt to merge the strengths of diffusion and autoregressive models, but they remain experimental and unproven at scale.
The Future of Text Generation: Uncertain Yet Exciting
Despite their current limitations, diffusion models may evolve into a transformative force in AI-driven creativity — if their accuracy challenges can be resolved.
Rewriting the Future: What’s Next for AI Text Generation?
Diffusion models are neither a clear improvement nor an outright failure — they represent a fork in the road for AI text generation. While they introduce efficiencies in fluency and style, their limitations in logical consistency and computational cost raise important questions about their long-term viability. As researchers experiment with hybrid solutions and optimization strategies, the future of AI-generated text remains a thrilling and uncertain frontier. Whether diffusion models will replace autoregressive methods or merely complement them is still an open question — one that AI engineers, businesses, and end-users must watch closely.
About Disruptive Concepts
Welcome to @Disruptive Concepts — your crystal ball into the future of technology. 🚀 Subscribe for new insight videos every Saturday!
See us on https://twitter.com/DisruptConcept
Read us on https://medium.com/@disruptiveconcepts
Enjoy us at https://disruptive-concepts.com
Whitepapers for you at: https://disruptiveconcepts.gumroad.com/l/emjml
New Apps: https://2025disruptive.netlify.app/
https://2025techhub.netlify.app/





