

What if the key to understanding the complex, dynamic world lies in teaching machines to see it as we do? Recent advancements in artificial intelligence (AI) suggest that we are closer than ever to unlocking this potential. The development of self-supervised learning (SSL) models capable of mastering 4D representations — capturing both spatial and temporal data — marks a groundbreaking moment in technology. In a new article, researchers delve into the cutting-edge research on scaling self-supervised video models, unraveling how a shift to massive architectures and novel methodologies is reshaping AI’s ability to interpret the geometry of motion.
What is 4D AI and Why Does It Matter?
Traditional AI models often excel in tasks involving static imagery or semantic understanding. However, these models falter when tasked with interpreting dynamic, spatial-temporal data, such as video. Here, 4D AI emerges as a transformative paradigm. By integrating 3D spatial data with the temporal dimension (hence 4D), these models mimic the dorsal stream in the human brain, which processes motion and transformations.
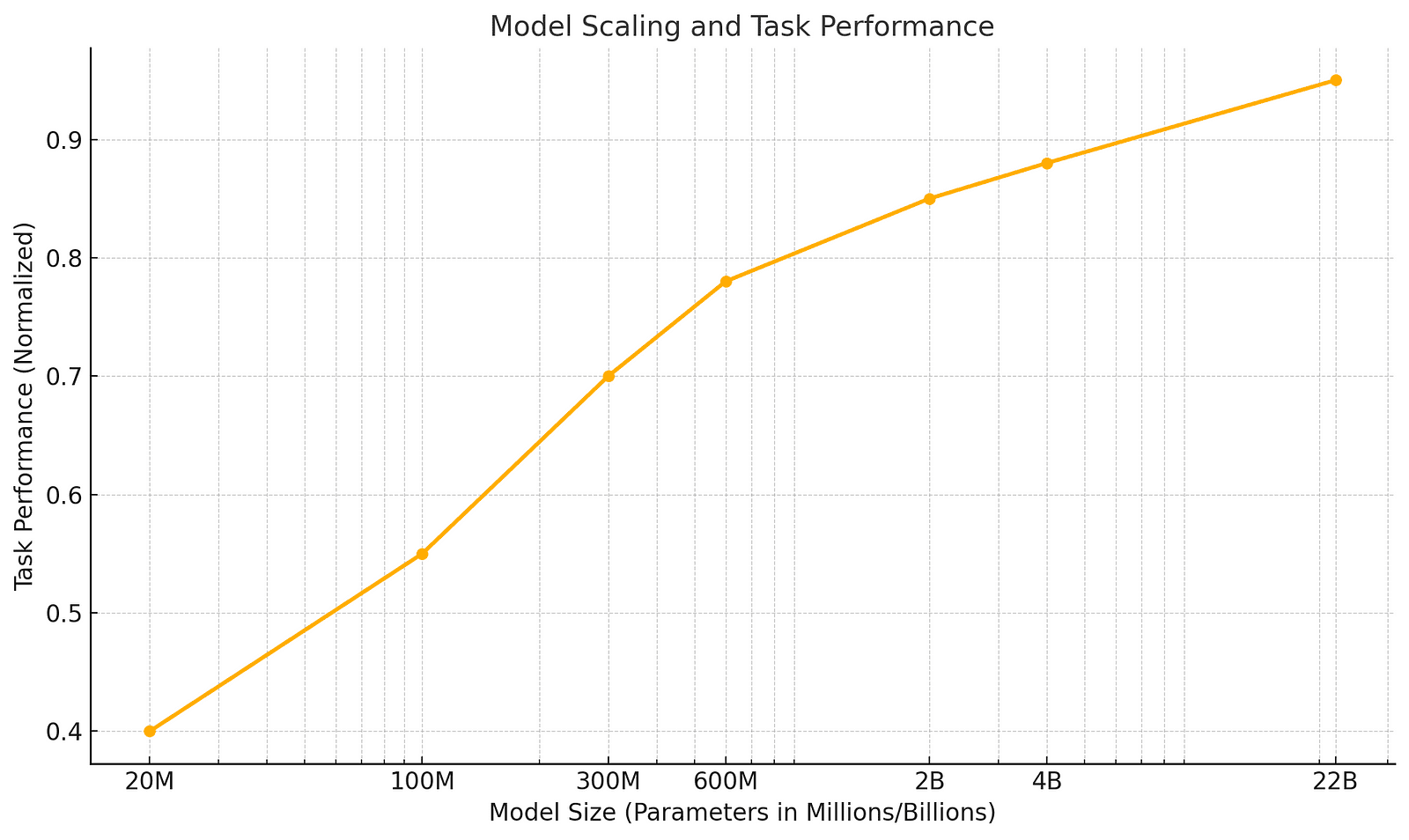
Recent research, particularly on Video Masked Auto-Encoders (Video MAE), has demonstrated the potential of self-supervised techniques. Unlike language-supervised approaches such as CLIP, SSL allows models to learn from vast datasets of unlabeled videos. These methods emphasize spatial-temporal coherence over semantic labeling, enabling breakthroughs in tasks like depth estimation, object tracking, and camera pose prediction. As the research shows, scaling these models from 20 million to a staggering 22 billion parameters amplifies their performance across multiple tasks.
How MAE Scaling Unlocks Unparalleled AI Potential
At the heart of this revolution lies the concept of Masked Auto-Encoders (MAE), which train models to reconstruct missing data. When applied to video, this approach masks 95% of the input frames, forcing the AI to infer missing information using spatial and temporal context. This technique not only boosts training efficiency but also enhances the model’s ability to generalize.
The “4DS” family of models, ranging from 20M to 22B parameters, exemplifies this innovation. These architectures scale effectively without the performance plateau often seen in smaller models. For instance, on tasks like depth estimation from the ScanNet dataset, the 22B model achieves state-of-the-art accuracy without relying on camera parameters.
The graph below illustrates how model performance improves exponentially with size:
The Future of AI Applications with 4D Vision
The ability of AI to decode the fourth dimension unlocks numerous real-world applications. Autonomous vehicles, for example, rely on depth estimation and object tracking to navigate complex environments. Similarly, advancements in camera pose estimation enable AR/VR systems to deliver immersive experiences by understanding spatial dynamics in real time.
However, challenges persist. Training these colossal models demands immense computational resources. The 22B model, for instance, required 20 days on 256 TPUs and a dataset of 170 million video clips. Additionally, questions about ethical data usage and energy consumption loom large. Despite these hurdles, the potential for 4D models to revolutionize industries remains undeniable.
How Machines Learn to Predict Missing Data
MAE forces models to infer 95% of masked frames, enhancing their ability to predict spatial and temporal dynamics.
Scaling to 22 Billion Parameters
The 22B 4DS model — the largest self-supervised video model to date — outperforms all prior benchmarks on geometry-focused tasks.
Beyond Semantics
Unlike language-supervised models, SSL excels at non-semantic tasks like camera pose estimation and depth prediction.
Efficiency in Training
The introduction of coarse grid decoding tokens reduces computational overhead, enabling scalable training.
Dorsal Stream Inspiration
4D AI mirrors the human brain’s dorsal stream, focusing on motion and transformation rather than static recognition.
Reimagining AI Through the Lens of 4D
The journey into 4D representation learning underscores the boundless possibilities of AI. By scaling self-supervised video models, researchers have opened new frontiers in spatial-temporal understanding, bridging the gap between human and machine perception. As we look ahead, the integration of 4D AI into autonomous systems, robotics, and immersive technologies promises a future where machines not only see the world but also move through it with human-like precision. The era of 4D AI has arrived, and its implications are both profound and inspiring.
About Disruptive Concepts
Welcome to @Disruptive Concepts — your crystal ball into the future of technology. 🚀 Subscribe for new insight videos every Saturday!
See us on https://twitter.com/DisruptConcept
Read us on https://medium.com/@disruptiveconcepts
Enjoy us at https://disruptive-concepts.com
Whitepapers for you at: https://disruptiveconcepts.gumroad.com/l/emjml





