
Transforming 1000 images into 3D models in seconds.

The quest for efficient and accurate 3D reconstruction has driven countless breakthroughs in computer vision, from traditional pipelines to modern neural networks. Enter Fast3R, a groundbreaking method that reconstructs over 1,000 unordered, unposed images in a single forward pass. Imagine a world where capturing the intricacies of a scene no longer takes hours or immense computational power. In this article, we’ll dive into how Fast3R transforms multi-view 3D reconstruction, paving the way for faster, more scalable solutions.
The Challenge of Multi-View 3D Reconstruction
From Bottlenecks to Breakthroughs: Why 3D Needs Fast3R
Traditional 3D reconstruction pipelines rely on tedious, step-by-step processes: matching image pairs, aligning features, and iterating to avoid errors. Approaches like Structure-from-Motion (SfM) have been foundational but remain plagued by scalability issues. DUSt3R emerged as a contender, introducing pointmap regression to simplify these processes. However, it faltered when tasked with processing more than two images simultaneously.
Fast3R tackles these limitations with an innovative Transformer-based architecture that handles multiple images at once. Unlike its predecessors, it eschews pairwise constraints, allowing every image to contribute to the 3D model simultaneously. This breakthrough ensures that increasing the number of views no longer leads to system crashes or diminishing returns.
Inside Fast3R’s Transformer Revolution
Fast3R’s Transformer: Redefining Speed and Scale
The heart of Fast3R lies in its Transformer-based design. Borrowing techniques from natural language processing, it employs all-to-all attention mechanisms, enabling simultaneous reasoning across all input images. The result? A system that’s not only faster but also significantly more accurate.
Fast3R’s architecture combines ViT (Vision Transformer) encoding, a robust fusion Transformer, and dense pointmap decoding. These elements work in harmony to predict global and local 3D structures with remarkable confidence. By training with randomized position embeddings, Fast3R adapts seamlessly to datasets with vastly different scales, from 20 images in training to over 1,000 during inference.
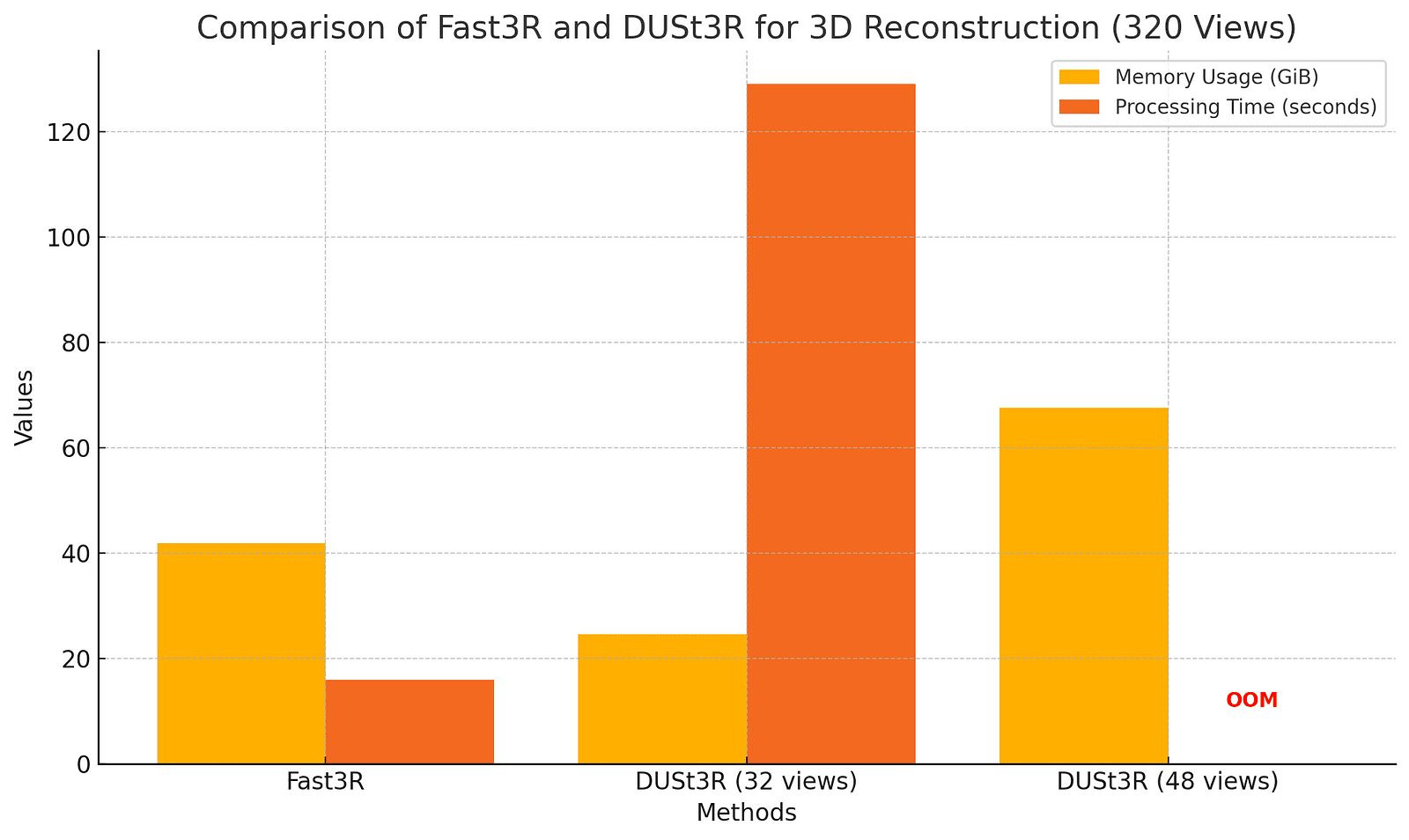
Fast3R’s efficiency compared to DUSt3R is undeniable. For instance, processing 320 views on an A100 GPU uses just 41.9 GiB of memory and takes under 16 seconds. Compare that to DUSt3R, which crashes beyond 32 views as Out of Memory (OOM).
Real-World Impact and Applications
Why Fast3R is a Game-Changer for AR, Robotics, and More
Fast3R’s capabilities extend far beyond benchmarks. In augmented reality, its real-time 3D modeling can redefine how we interact with virtual environments. Robotics, too, stands to gain, as Fast3R’s accuracy in camera pose estimation ensures better navigation and object manipulation.
On datasets like CO3Dv2, Fast3R achieves a near-perfect 99.7% accuracy within 15 degrees for pose estimation. Its ability to scale without compromising quality opens doors to applications in urban mapping, archaeological preservation, and even cinematic effects.
The Power of Parallel Processing
Fast3R processes over 1,000 images simultaneously, a feat that took traditional methods hours. Its Transformer-based design ensures no image is left behind.
Near-Perfect Pose Accuracy
On CO3Dv2, Fast3R achieves 99.7% pose estimation accuracy within 15 degrees, outperforming competitors by over 14x in error reduction.
From 320 to 1,500 Views Without Crashing
Fast3R thrives where others fail, processing up to 1,500 images in one pass on a single GPU, thanks to its memory-efficient architecture.
Speed That Stuns
At 251 FPS, Fast3R is 200x faster than DUSt3R, making real-time applications a reality.
A New Standard for 3D Reconstruction
Fast3R simplifies 3D modeling, offering unmatched scalability and accuracy for researchers and industries alike.
Fast3R and the Future of 3D Technology
Fast3R signals a turning point in 3D reconstruction, blending speed, scalability, and precision. Its Transformer-powered approach eliminates the bottlenecks of traditional methods, enabling a future where 3D imaging is accessible, efficient, and limitless. As industries embrace this breakthrough, the dream of real-time, high-fidelity 3D modeling becomes a reality.
About Disruptive Concepts
Welcome to @Disruptive Concepts — your crystal ball into the future of technology. 🚀 Subscribe for new insight videos every Saturday!
See us on https://twitter.com/DisruptConcept
Read us on https://medium.com/@disruptiveconcepts
Enjoy us at https://disruptive-concepts.com
Whitepapers for you at: https://disruptiveconcepts.gumroad.com/l/emjml
New Apps: https://2025disruptive.netlify.app/





