

Imagine being able to identify a person just by their voice, no matter the background noise or environment. This is the exciting world of speaker recognition technology. The new framework developed researchers focuses on disentangling speaker information from environmental noise, ensuring that AI can accurately recognize voices in any setting. This is done using an auto-encoder that separates the speaker’s voice characteristics from other sounds.
This technology is groundbreaking because it makes AI speaker recognition reliable even in noisy places like busy streets or crowded cafes. This is like having a superpower that allows you to recognize your friends by their voice, even at a loud party. The team’s framework not only enhances the accuracy of speaker recognition but also ensures that it can be used seamlessly with existing systems. This means better, more reliable voice assistants and security systems that can work anywhere, anytime.
The Future of Speaker Recognition in AI
In the realm of AI, the ability to distinguish between speakers accurately is a game-changer. Traditional systems often struggle with background noise, which can distort the voice signal and make recognition difficult. The new framework tackles this problem head-on by using an auto-encoder to filter out environmental noise. This makes the system robust and effective across various conditions.
Imagine trying to recognize a friend’s voice in a noisy cafeteria. Traditional AI might struggle, but this new approach ensures it can still accurately identify the speaker. This advancement is crucial for applications in security, where accurate voice recognition can prevent unauthorized access. For a teenager, this technology could mean better voice-activated gadgets that work flawlessly in any environment, from school hallways to busy streets.
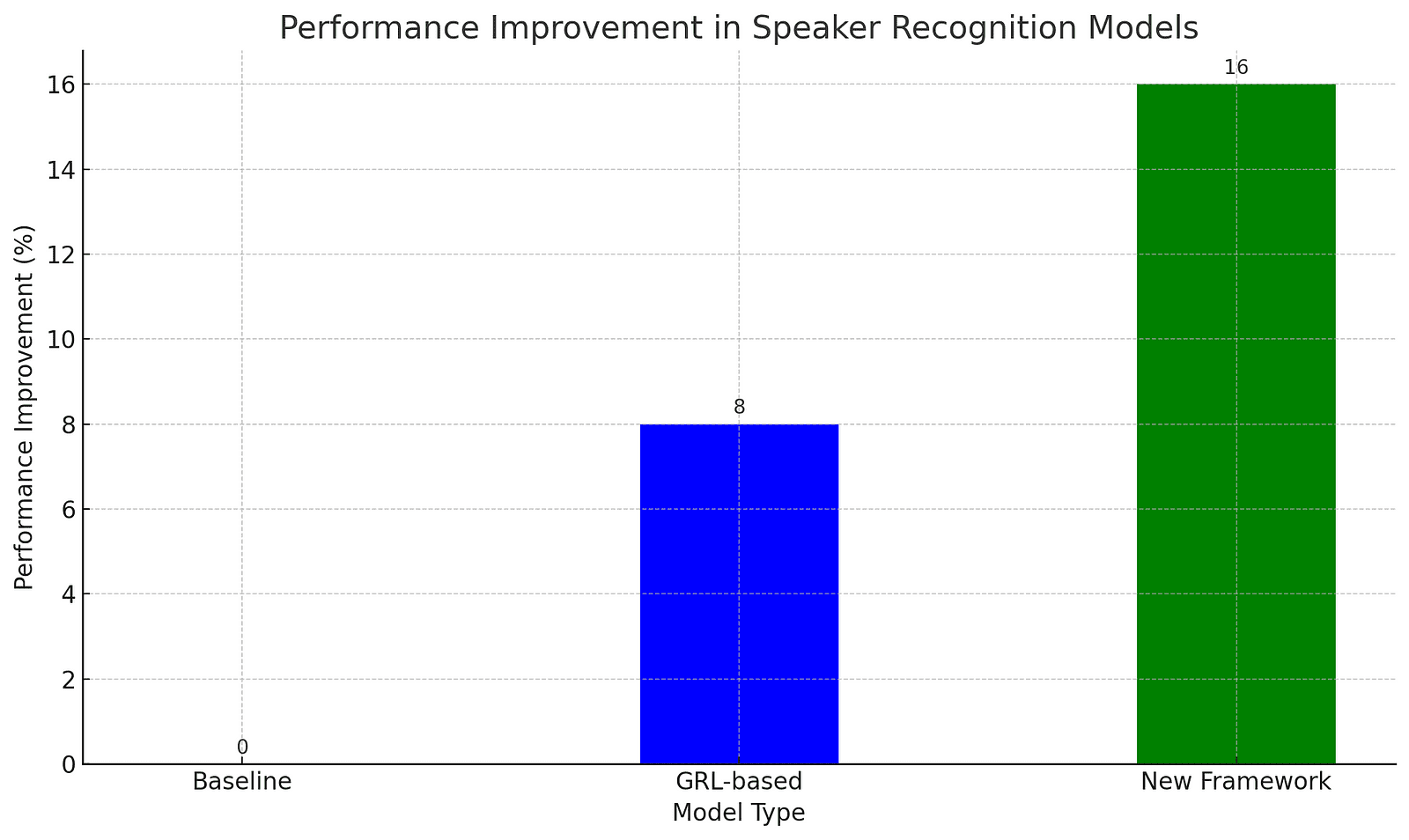
The researchers have tested their framework extensively and found it improves performance by up to 16%. This makes it not just a theoretical improvement but a practical solution that can be implemented in real-world scenarios, ensuring reliable and consistent performance.
The Breakthrough in Speaker Recognition Technology
The world of speaker recognition is evolving, and at the heart of this evolution is the need to separate essential voice characteristics from background noise. The new framework uses a sophisticated auto-encoder to achieve this separation. This technology ensures that AI systems can focus on the voice itself, ignoring the irrelevant noise that often confuses traditional systems.
Think of it as a pair of magical headphones that allow you to hear someone clearly, even in a noisy environment. This is exactly what this new AI framework does. It makes speaker recognition more accurate and reliable, which is essential for applications in security and personal assistants. For a young audience, this technology promises voice-activated devices that understand you perfectly, regardless of the surrounding noise.
This advancement opens up new possibilities for AI, making it more adaptable and efficient. It also highlights the importance of continuous innovation in making technology more user-friendly and effective in real-world situations.
To illustrate the effectiveness of the new speaker recognition framework, here is a graph below comparing the performance improvement of the baseline model, GRL-based model, and the new framework across various benchmarks.
Echoes of the Future
As AI continues to integrate into our daily lives, the ability to accurately recognize voices becomes increasingly important. The innovative framework represents a significant leap forward in this field.
Environment-Agnostic Recognition
The new framework enables AI systems to recognize voices accurately in any environment by disentangling speaker characteristics from background noise. This makes AI applications more reliable and versatile.
Auto-Encoder Technology
The use of an auto-encoder allows the system to focus on the essential features of the speaker’s voice, filtering out irrelevant environmental sounds. This results in a significant improvement in recognition accuracy.
Performance Improvement
The framework has been tested extensively, showing up to a 16% improvement in performance compared to traditional methods. This makes it a practical solution for real-world applications.
Compatibility with Existing Systems
The framework is designed to integrate seamlessly with existing speaker recognition systems, requiring no major modifications. This ensures that the technology can be widely adopted.
Real-World Applications
From personal assistants to security systems, this technology enhances the reliability and accuracy of AI applications in various real-world scenarios, making it a valuable advancement.
A Future of Clear Communication
The advancements in speaker recognition technology are paving the way for a future where AI can understand and interact with us flawlessly, no matter the environment. This framework ensures that voices are recognized accurately, making AI more reliable and efficient. For young tech enthusiasts, this is a glimpse into a future where technology works seamlessly with us, enhancing every aspect of our lives. The promise of AI that can hear and understand us perfectly is no longer a distant dream but a rapidly approaching reality.
About Disruptive Concepts
https://www.disruptive-concepts.com/
Welcome to @Disruptive Concepts — your crystal ball into the future of technology. 🚀 Subscribe for new insight videos every Saturday!
Discover the Must-Have Kitchen Gadgets of 2024! From ZeroWater Filters to Glass Containers, Upgrade Your Home with Essential Tools for Safety and Sustainability. Click Here to Transform Your Kitchen Today!





