

When you think of artificial intelligence, you might picture robots doing your chores or algorithms deciding what movie you should watch next. But what if AI could look at pictures and text together and understand them as you do? MM-Vet v2 is here to test just that. Developed to evaluate Large Multimodal Models (LMMs), MM-Vet v2 is a benchmark that doesn’t just check if a machine can understand an image or a sentence but sees if it can understand both, together, in a sequence, much like how you follow a storybook with pictures and words.
Now, why does this matter? Imagine if your virtual assistant could understand complex information presented in manuals or even scientific papers with images and text, then explain it to you in a way you understand. MM-Vet v2 tests this potential, pushing the boundaries of what’s possible with AI. It adds a new layer to the evaluation by testing image-text sequence understanding, which challenges models to comprehend intertwined streams of visual and textual data. Think of MM-Vet v2 as the ultimate test for machines, one that checks if they’re ready to think and understand like humans.
The Future of Learning
LMMs are evolving at an astonishing pace, and MM-Vet v2 is helping them do it better. But what’s an LMM anyway? It’s like a super brain that combines different types of information — like what you see and read — to make sense of the world. Imagine having a model that can recognize a cat in a picture, know that the caption says, “The cat is playing,” and understand how those two are connected to make a story. This is the kind of intelligence LMMs are reaching for, and MM-Vet v2 is their training ground.
The introduction of image-text sequence understanding means models aren’t just matching pictures to words. They’re making connections across frames of a video or pages of a comic book. With 517 questions spanning scenarios from everyday life to expert fields, MM-Vet v2 is like a school for AI, offering lessons in logic, sequence, and context. It challenges machines to think deeper and learn how images and text interact in real-world scenarios. This sets the stage for future advancements, where your AI-powered devices can become even more intuitive and insightful.
The Battle for AI Supremacy: Who Leads the Pack?
In the world of AI, not all models are created equal, and MM-Vet v2 is here to separate the leaders from the followers. The benchmark pits models against each other, using a scoring system to determine which can think and understand best. As of now, Claude 3.5 Sonnet takes the crown, scoring 71.8, with GPT-4o hot on its heels at 71.0. These scores reflect how well the models can tackle the benchmark’s challenges, from recognizing objects to generating language and beyond.
For those interested in the open-weight category, InternVL2-Llama3–76B shines bright, boasting a competitive score of 68.4. The MM-Vet v2 leaderboard isn’t just a ranking. It’s a reflection of the AI landscape, showcasing the models that are pushing the envelope in multimodal understanding. It’s like a high-stakes competition where the prize is the advancement of AI technology that can truly understand and interact with the world like never before.
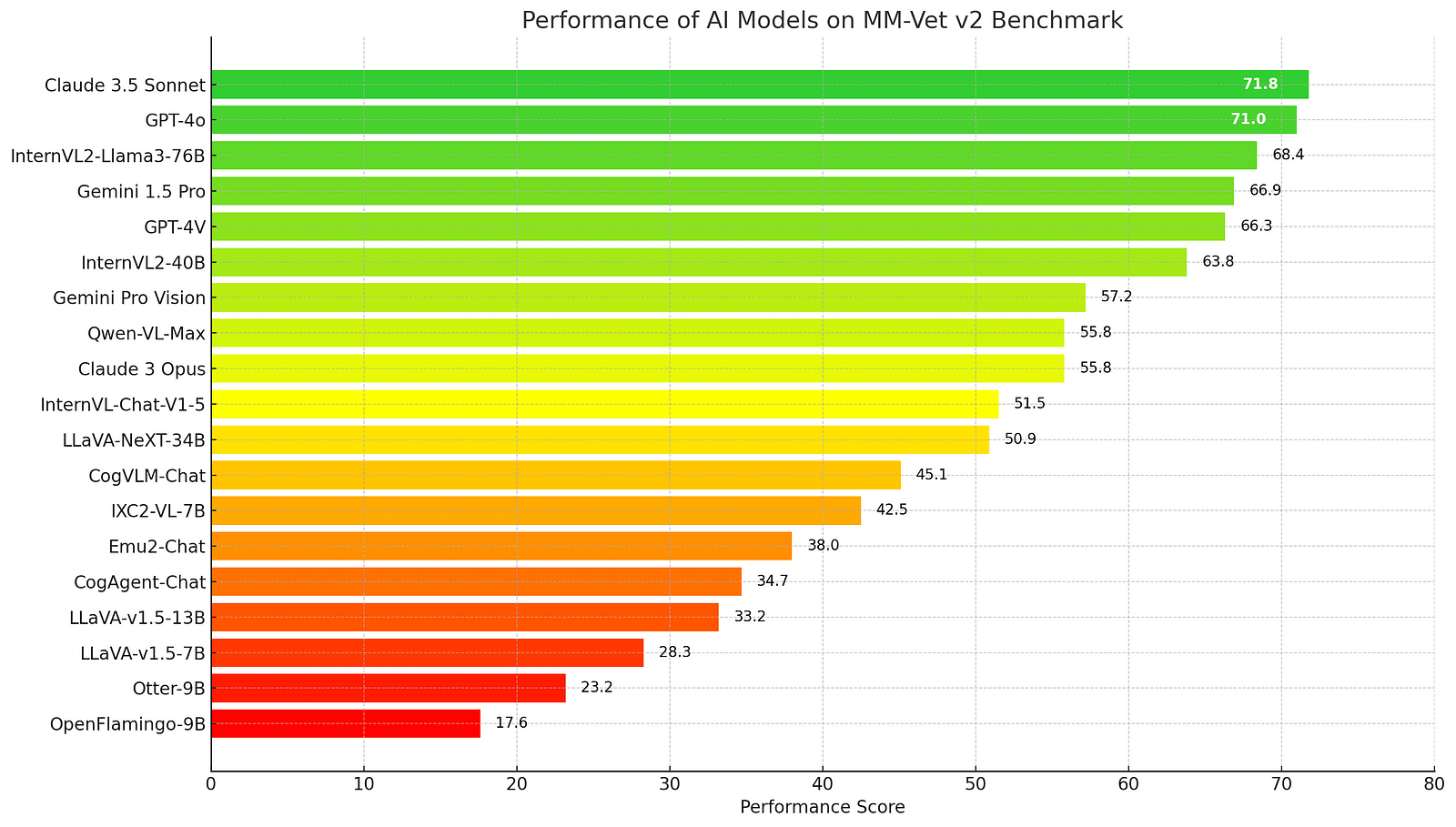
The graph above displays the performance scores of various AI models on the MM-Vet v2 benchmark. Claude 3.5 Sonnet and GPT-4o emerge as top performers, showcasing their exceptional capabilities in multimodal understanding. This visualization provides a clear overview of the competitive landscape in AI development, highlighting the strengths and differences among leading models.
Why MM-Vet v2 Matters
So, why should you care about MM-Vet v2? Because it’s setting the stage for the AI of tomorrow. By challenging models to think like humans, it’s opening doors to innovations that once seemed like science fiction. Imagine robots that can read instruction manuals, personal assistants that understand complex documents, and educational tools that teach in ways that adapt to how you learn best. MM-Vet v2 is more than just a test; it’s a stepping stone to a future where AI partners with humans to solve problems, explore new worlds, and enhance our everyday lives.
For the curious minds intrigued by technology’s potential, MM-Vet v2 is a beacon of inspiration. It’s a reminder that the machines of today are learning to become the helpful, intelligent assistants of tomorrow. As we continue to develop and refine these models, the possibilities become endless, limited only by our imagination and the challenges we dare to overcome.
Understanding Beyond Images
MM-Vet v2 has introduced the ability for AI models to understand sequences of images and text. This is groundbreaking because it mimics how we process visual stories in comic strips or instructions in manuals. By requiring models to interpret these sequences, MM-Vet v2 sets a higher standard for AI, encouraging the development of models that can engage with complex visual narratives. This leap in understanding is crucial for applications like advanced robotics and AI-driven education tools.
The Comprehensive Test
With 517 questions designed to stretch the capabilities of AI models, MM-Vet v2 doesn’t make it easy for machines. It covers a range of scenarios, from simple daily tasks to complex industry applications. This wide array of questions ensures that the models are not just memorizing answers but are learning to adapt and think critically. Such a challenging benchmark fosters the creation of more intelligent systems capable of real-world applications.
From Science to Art
The evaluation set in MM-Vet v2 isn’t just about logic and numbers. It spans various domains, including art, science, and everyday life. This diversity in evaluation is key to developing AI that can think creatively and apply knowledge across different fields. By testing models on such a broad spectrum, MM-Vet v2 paves the way for AI to become a versatile tool, aiding in creative endeavors as much as analytical tasks.
The Top Contenders
Claude 3.5 Sonnet and GPT-4o have emerged as top contenders in the race for AI supremacy, each excelling in different aspects of the MM-Vet v2 benchmark. While Claude 3.5 Sonnet scores high in recognition and language generation, GPT-4o excels in image-text sequence understanding. This competitive environment drives innovation, pushing models to improve and set new standards in AI capabilities.
The Human Touch
MM-Vet v2’s approach to evaluating AI reflects a shift toward human-like understanding. By challenging models to process and understand sequences like a human, the benchmark encourages the development of AI that can think and learn in more intuitive ways. This human-centric approach is essential for creating AI systems that can integrate seamlessly into our daily lives, offering assistance that feels natural and responsive.
Toward a Bright AI Future
As we stand on the brink of a new era in AI, MM-Vet v2 is a catalyst for change. Its unique approach to testing the integrated capabilities of multimodal models inspires the creation of AI systems that understand and interact with the world in more sophisticated ways. Imagine a future where your AI can read and interpret complex documents, assist in creative projects, and adapt to your personal learning style. This isn’t just a dream but a burgeoning reality, thanks to the pioneering efforts of MM-Vet v2. As we continue to push the boundaries of what’s possible, one thing is clear: the future of AI is bright, and the possibilities are endless.
About Disruptive Concepts
https://www.disruptive-concepts.com/
Welcome to @Disruptive Concepts — your crystal ball into the future of technology. 🚀 Subscribe for new insight videos every Saturday!
Discover the Must-Have Kitchen Gadgets of 2024! From ZeroWater Filters to Glass Containers, Upgrade Your Home with Essential Tools for Safety and Sustainability. Click Here to Transform Your Kitchen Today!





